Comparing visual artifacts can be a powerful, if fickle, approach to automated testing. Playwright makes this seem simple for websites, but the details might take a little finessing.
Recent downtime prompted me to scratch an itch that had been plaguing me for a while: The style sheet of a website I maintain has grown just a little unwieldy as we’ve been adding code while exploring new features. Now that we have a better idea of the requirements, it’s time for internal CSS refactoring to pay down some of our technical debt, taking advantage of modern CSS features (like using CSS nesting for more obvious structure). More importantly, a cleaner foundation should make it easier to introduce that dark mode feature we’re sorely lacking so we can finally respect users’ preferred color scheme.
However, being of the apprehensive persuasion, I was reluctant to make large changes for fear of unwittingly introducing bugs. I needed something to guard against visual regressions while refactoring — except that means snapshot testing, which is notoriously slow and brittle.
In this context, snapshot testing means taking screenshots to establish a reliable baseline against which we can compare future results. As we’ll see, those artifacts are influenced by a multitude of factors that might not always be fully controllable (e.g. timing, variable hardware resources, or randomized content). We also have to maintain state between test runs, i.e. save those screenshots, which complicates the setup and means our test code alone doesn’t fully describe expectations.
Having procrastinated without a more agreeable solution revealing itself, I finally set out to create what I assumed would be a quick spike. After all, this wouldn’t be part of the regular test suite; just a one-off utility for this particular refactoring task.
Fortunately, I had vague recollections of past research and quickly rediscovered Playwright’s built-in visual comparison feature. Because I try to select dependencies carefully, I was glad to see that Playwright seems not to rely on many external packages.
Setup
Table of Contents
The recommended setup with npm init playwright@latest does a decent job, but my minimalist taste had me set everything up from scratch instead. This do-it-yourself approach also helped me understand how the different pieces fit together.
Given that I expect snapshot testing to only be used on rare occasions, I wanted to isolate everything in a dedicated subdirectory, called test/visual; that will be our working directory from here on out. We’ll start with package.json to declare our dependencies, adding a few helper scripts (spoiler!) while we’re at it:
{
"scripts": {
"test": "playwright test",
"report": "playwright show-report",
"update": "playwright test --update-snapshots",
"reset": "rm -r ./playwright-report ./test-results ./viz.test.js-snapshots || true"
},
"devDependencies": {
"@playwright/test": "^1.49.1"
}
}If you don’t want node_modules hidden in some subdirectory but also don’t want to burden the root project with this rarely-used dependency, you might resort to manually invoking npm install --no-save @playwright/test in the root directory when needed.
With that in place, npm install downloads Playwright. Afterwards, npx playwright install downloads a range of headless browsers. (We’ll use npm here, but you might prefer a different package manager and task runner.)
We define our test environment via playwright.config.js with about a dozen basic Playwright settings:
import { defineConfig, devices } from "@playwright/test";
let BROWSERS = ["Desktop Firefox", "Desktop Chrome", "Desktop Safari"];
let BASE_URL = "http://localhost:8000";
let SERVER = "cd ../../dist && python3 -m http.server";
let IS_CI = !!process.env.CI;
export default defineConfig({
testDir: "./",
fullyParallel: true,
forbidOnly: IS_CI,
retries: 2,
workers: IS_CI ? 1 : undefined,
reporter: "html",
webServer: {
command: SERVER,
url: BASE_URL,
reuseExistingServer: !IS_CI
},
use: {
baseURL: BASE_URL,
trace: "on-first-retry"
},
projects: BROWSERS.map(ua => ({
name: ua.toLowerCase().replaceAll(" ", "-"),
use: { ...devices[ua] }
}))
});Here we expect our static website to already reside within the root directory’s dist folder and to be served at localhost:8000 (see SERVER; I prefer Python there because it’s widely available). I’ve included multiple browsers for illustration purposes. Still, we might reduce that number to speed things up (thus our simple BROWSERS list, which we then map to Playwright’s more elaborate projects data structure). Similarly, continuous integration is YAGNI for my particular scenario, so that whole IS_CI dance could be discarded.
Capture and compare
Let’s turn to the actual tests, starting with a minimal sample.test.js file:
import { test, expect } from "@playwright/test";
test("home page", async ({ page }) => {
await page.goto("/");
await expect(page).toHaveScreenshot();
});npm test executes this little test suite (based on file-name conventions). The initial run always fails because it first needs to create baseline snapshots against which subsequent runs compare their results. Invoking npm test once more should report a passing test.
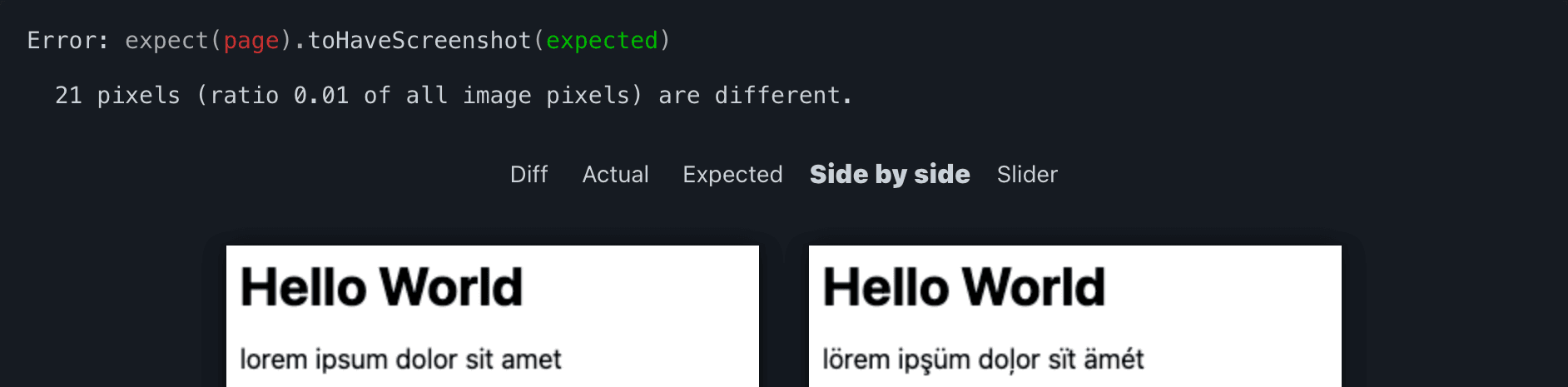
Changing our site, e.g. by recklessly messing with build artifacts in dist, should make the test fail again. Such failures will offer various options to compare expected and actual visuals:
We can also inspect those baseline snapshots directly: Playwright creates a folder for screenshots named after the test file (sample.test.js-snapshots in this case), with file names derived from the respective test’s title (e.g. home-page-desktop-firefox.png).
Generating tests
Getting back to our original motivation, what we want is a test for every page. Instead of arduously writing and maintaining repetitive tests, we’ll create a simple web crawler for our website and have tests generated automatically; one for each URL we’ve identified.
Playwright’s global setup enables us to perform preparatory work before test discovery begins: Determine those URLs and write them to a file. Afterward, we can dynamically generate our tests at runtime.
While there are other ways to pass data between the setup and test-discovery phases, having a file on disk makes it easy to modify the list of URLs before test runs (e.g. temporarily ignoring irrelevant pages).
Site map
The first step is to extend playwright.config.js by inserting globalSetup and exporting two of our configuration values:
export let BROWSERS = ["Desktop Firefox", "Desktop Chrome", "Desktop Safari"];
export let BASE_URL = "http://localhost:8000";
// etc.
export default defineConfig({
// etc.
globalSetup: require.resolve("./setup.js")
});Although we’re using ES modules here, we can still rely on CommonJS-specific APIs like require.resolve and __dirname. It appears there’s some Babel transpilation happening in the background, so what’s actually being executed is probably CommonJS? Such nuances sometimes confuse me because it isn’t always obvious what’s being executed where.
We can now reuse those exported values within a newly created setup.js, which spins up a headless browser to crawl our site (just because that’s easier here than using a separate HTML parser):
import { BASE_URL, BROWSERS } from "./playwright.config.js";
import { createSiteMap, readSiteMap } from "./sitemap.js";
import playwright from "@playwright/test";
export default async function globalSetup(config) {
// only create site map if it doesn't already exist
try {
readSiteMap();
return;
} catch(err) {}
// launch browser and initiate crawler
let browser = playwright.devices[BROWSERS[0]].defaultBrowserType;
browser = await playwright[browser].launch();
let page = await browser.newPage();
await createSiteMap(BASE_URL, page);
await browser.close();
}This is fairly boring glue code; the actual crawling is happening within sitemap.js:
createSiteMapdetermines URLs and writes them to disk.readSiteMapmerely reads any previously created site map from disk. This will be our foundation for dynamically generating tests. (We’ll see later why this needs to be synchronous.)
Fortunately, the website in question provides a comprehensive index of all pages, so my crawler only needs to collect unique local URLs from that index page:
function extractLocalLinks(baseURL) {
let urls = new Set();
let offset = baseURL.length;
for(let { href } of document.links) {
if(href.startsWith(baseURL)) {
let path = href.slice(offset);
urls.add(path);
}
}
return Array.from(urls);
}Wrapping that in a more boring glue code gives us our sitemap.js:
import { readFileSync, writeFileSync } from "node:fs";
import { join } from "node:path";
let ENTRY_POINT = "/topics";
let SITEMAP = join(__dirname, "./sitemap.json");
export async function createSiteMap(baseURL, page) {
await page.goto(baseURL + ENTRY_POINT);
let urls = await page.evaluate(extractLocalLinks, baseURL);
let data = JSON.stringify(urls, null, 4);
writeFileSync(SITEMAP, data, { encoding: "utf-8" });
}
export function readSiteMap() {
try {
var data = readFileSync(SITEMAP, { encoding: "utf-8" });
} catch(err) {
if(err.code === "ENOENT") {
throw new Error("missing site map");
}
throw err;
}
return JSON.parse(data);
}
function extractLocalLinks(baseURL) {
// etc.
}The interesting bit here is that extractLocalLinks is evaluated within the browser context — thus we can rely on DOM APIs, notably document.links — while the rest is executed within the Playwright environment (i.e. Node).
Tests
Now that we have our list of URLs, we basically just need a test file with a simple loop to dynamically generate corresponding tests:
for(let url of readSiteMap()) {
test(`page at ${url}`, async ({ page }) => {
await page.goto(url);
await expect(page).toHaveScreenshot();
});
}This is why readSiteMap had to be synchronous above: Playwright doesn’t currently support top-level await within test files.
In practice, we’ll want better error reporting for when the site map doesn’t exist yet. Let’s call our actual test file viz.test.js:
import { readSiteMap } from "./sitemap.js";
import { test, expect } from "@playwright/test";
let sitemap = [];
try {
sitemap = readSiteMap();
} catch(err) {
test("site map", ({ page }) => {
throw new Error("missing site map");
});
}
for(let url of sitemap) {
test(`page at ${url}`, async ({ page }) => {
await page.goto(url);
await expect(page).toHaveScreenshot();
});
}Getting here was a bit of a journey, but we’re pretty much done… unless we have to deal with reality, which typically takes a bit more tweaking.
Exceptions
Because visual testing is inherently flaky, we sometimes need to compensate via special casing. Playwright lets us inject custom CSS, which is often the easiest and most effective approach. Tweaking viz.test.js…
// etc.
import { join } from "node:path";
let OPTIONS = {
stylePath: join(__dirname, "./viz.tweaks.css")
};
// etc.
await expect(page).toHaveScreenshot(OPTIONS);
// etc.… allows us to define exceptions in viz.tweaks.css:
/* suppress state */
main a:visited {
color: var(--color-link);
}
/* suppress randomness */
iframe[src$="/articles/signals-reactivity/demo.html"] {
visibility: hidden;
}
/* suppress flakiness */
body:has(h1 a[href="/wip/unicode-symbols/"]) {
main tbody > tr:last-child > td:first-child {
font-size: 0;
visibility: hidden;
}
}:has() strikes again!
Page vs. viewport
At this point, everything seemed hunky-dory to me, until I realized that my tests didn’t actually fail after I had changed some styling. That’s not good! What I hadn’t taken into account is that .toHaveScreenshot only captures the viewport rather than the entire page. We can rectify that by further extending playwright.config.js.
export let WIDTH = 800;
export let HEIGHT = WIDTH;
// etc.
projects: BROWSERS.map(ua => ({
name: ua.toLowerCase().replaceAll(" ", "-"),
use: {
...devices[ua],
viewport: {
width: WIDTH,
height: HEIGHT
}
}
}))…and then by adjusting viz.test.js‘s test-generating loop:
import { WIDTH, HEIGHT } from "./playwright.config.js";
// etc.
for(let url of sitemap) {
test(`page at ${url}`, async ({ page }) => {
checkSnapshot(url, page);
});
}
async function checkSnapshot(url, page) {
// determine page height with default viewport
await page.setViewportSize({
width: WIDTH,
height: HEIGHT
});
await page.goto(url);
await page.waitForLoadState("networkidle");
let height = await page.evaluate(getFullHeight);
// resize viewport for before snapshotting
await page.setViewportSize({
width: WIDTH,
height: Math.ceil(height)
});
await page.waitForLoadState("networkidle");
await expect(page).toHaveScreenshot(OPTIONS);
}
function getFullHeight() {
return document.documentElement.getBoundingClientRect().height;
}Note that we’ve also introduced a waiting condition, holding until there’s no network traffic for a while in a crude attempt to account for stuff like lazy-loading images.
Be aware that capturing the entire page is more resource-intensive and doesn’t always work reliably: You might have to deal with layout shifts or run into timeouts for long or asset-heavy pages. In other words: This risks exacerbating flakiness.
Conclusion
So much for that quick spike. While it took more effort than expected (I believe that’s called “software development”), this might actually solve my original problem now (not a common feature of software these days). Of course, shaving this yak still leaves me itchy, as I have yet to do the actual work of scratching CSS without breaking anything. Then comes the real challenge: Retrofitting dark mode to an existing website. I just might need more downtime.